Note基于开源 kafka 2.5 版本。
如无特殊说明,文中代码片段将删除 debug 信息、异常触发、英文注释等代码,以便观看核心代码。
本篇跟随胡夕大佬的步伐,本篇开启 kafka 客户端请求与响应的源码阅读,特别是针对请求队列源码进行分析。
我分析代码喜欢自上而下地分析,但是因为自己摸索比较费时间,因此先跟随大佬一块块弄懂,可能会显得有点乱。最后可能再将该系列博客更新为由上至下的分析。
请求
首先看到 RequestChannel.scala 文件,该文件包含了请求和响应类的定义,以及处理请求与响应的相关代码,这些代码均封装在RequestChannel这个类中,这个类我们之后会分析,首先看一下请求类的定义:
sealed trait BaseRequest
// 用于通知请求处理器(RequestHandler)broker关闭事件,只在内部进行使用
case object ShutdownRequest extends BaseRequest
class Request(
// 请求所属的处理线程编号
val processor: Int,
// 请求的参数(addr、header等)
val context: RequestContext,
// 请求对象被创建的时间,用于监控指标
val startTimeNanos: Long,
// 缓冲对象池,用于复用缓冲对象,减少gc压力
memoryPool: MemoryPool,
// 请求体
@volatile private var buffer: ByteBuffer,
// 管理监控指标
metrics: RequestChannel.Metrics
) extends BaseRequest {
// ...
}
processor指明了该请求由哪个 processor 线程进行处理。processor 线程的数量由 broker 的 num.network.threads 参数决定,processor 负责处理网络请求的接收和响应。因此请求的processor参数是为了便于追踪请求由哪个 processor 线程处理、监控每个 processor 的负载等。
context保存了该请求的所有上下文信息,并且还能解析出真正的 request 及其大小。
public class RequestContext implements AuthorizableRequestContext {
public final RequestHeader header;
public final String connectionId;
public final InetAddress clientAddress;
public final KafkaPrincipal principal;
public final ListenerName listenerName;
public final SecurityProtocol securityProtocol;
public final ClientInformation clientInformation;
public RequestAndSize parseRequest(ByteBuffer buffer) {
// ...
}
}
startTimeNanos以纳秒为单位的时间戳,实现细粒度的时间统计。
memoryPool提供了一个内存对象池,用来复用对象。有三个不同的实现,后面会细说。
buffer保存了该请求的真正内容,由上面context的parseRequest方法进行解析。
metrics面构建了一个 Map,封装了所有的请求 JMX 指标,所谓 JMX 是一个 Java 平台的管理和监控接口。
最后再看一下 RequestContext 中较为核心的 parseRequest 方法,这个方法将字节缓冲解析为具体的请求对象:
public RequestAndSize parseRequest(ByteBuffer buffer) {
if (isUnsupportedApiVersionsRequest()) {
// 不支持的api版本,视为request v0
ApiVersionsRequest apiVersionsRequest = new ApiVersionsRequest(new ApiVersionsRequestData(), (short) 0, header.apiVersion());
return new RequestAndSize(apiVersionsRequest, 0);
} else {
// 获取api的类型(比如有Produce, OffsetCommit等类型的api)
ApiKeys apiKey = header.apiKey();
try {
// 获取请求的api版本
short apiVersion = header.apiVersion();
// 将字节缓冲解析为struct
Struct struct = apiKey.parseRequest(apiVersion, buffer);
// 将struct解析为具体的请求对象
AbstractRequest body = AbstractRequest.parseRequest(apiKey, apiVersion, struct);
// 返回请求对象及其大小
return new RequestAndSize(body, struct.sizeOf());
} catch (Throwable ex) {
throw new InvalidRequestException("Error getting request for apiKey: " + apiKey +
", apiVersion: " + header.apiVersion() +
", connectionId: " + connectionId +
", listenerName: " + listenerName +
", principal: " + principal, ex);
}
}
}
这里有一个很重要的枚举类型ApiKeys,主要是定义了每个 API 对应的请求与响应模板(schema),比如 Produce API、Fetch API:
public enum ApiKeys {
PRODUCE(0, "Produce", ProduceRequest.schemaVersions(), ProduceResponse.schemaVersions()),
FETCH(1, "Fetch", FetchRequest.schemaVersions(), FetchResponse.schemaVersions()),
// ...
}
另外,注意到 RequestContext 的 parseRequest 解析 buffer 的流程是先将其转换为 Struct 再通过 AbstractRequest.parseRequest 根据不同的 api 类型构造具体的请求对象。这样做的好处在于统一了从字节缓冲解析字段的代码逻辑,提高代码复用度。代码如下所示:
@Override
public Struct read(ByteBuffer buffer) {
Object[] objects = new Object[fields.length];
for (int i = 0; i < fields.length; i++) {
try {
if (tolerateMissingFieldsWithDefaults) {
if (buffer.hasRemaining()) {
// 根据schema中的字段定义,从buffer中读取字段保存到数组中,方便后续取出
objects[i] = fields[i].def.type.read(buffer);
} else if (fields[i].def.hasDefaultValue) {
objects[i] = fields[i].def.defaultValue;
} else {
throw new SchemaException("Missing value for field '" + fields[i].def.name +
"' which has no default value.");
}
} else {
objects[i] = fields[i].def.type.read(buffer);
}
} catch (Exception e) {
throw new SchemaException("Error reading field '" + fields[i].def.name + "': " + (e.getMessage() == null ? e.getClass().getName() : e.getMessage()));
}
}
return new Struct(this, objects);
}
随后就是将该 Struct 传给 AbstractRequest.parseRequest 去构造具体的请求对象:
public static AbstractRequest parseRequest(ApiKeys apiKey, short apiVersion, Struct struct) {
switch (apiKey) {
case PRODUCE:
return new ProduceRequest(struct, apiVersion);
case FETCH:
return new FetchRequest(struct, apiVersion);
case LIST_OFFSETS:
return new ListOffsetRequest(struct, apiVersion);
// ...
default:
throw new AssertionError(String.format("ApiKey %s is not currently handled in `parseRequest`, the " + "code should be updated to do so.", apiKey));
}
}
来看一个具体的请求对象如何构造:
public ProduceRequest(Struct struct, short version) {
super(ApiKeys.PRODUCE, version);
partitionRecords = new HashMap<>();
// struct.getArray
for (Object topicDataObj : struct.getArray(TOPIC_DATA_KEY_NAME)) {
Struct topicData = (Struct) topicDataObj;
String topic = topicData.get(TOPIC_NAME);
for (Object partitionResponseObj : topicData.getArray(PARTITION_DATA_KEY_NAME)) {
Struct partitionResponse = (Struct) partitionResponseObj;
int partition = partitionResponse.get(PARTITION_ID);
MemoryRecords records = (MemoryRecords) partitionResponse.getRecords(RECORD_SET_KEY_NAME);
setFlags(records);
partitionRecords.put(new TopicPartition(topic, partition), records);
}
}
partitionSizes = createPartitionSizes(partitionRecords);
// struct.getShort
acks = struct.getShort(ACKS_KEY_NAME);
timeout = struct.getInt(TIMEOUT_KEY_NAME);
transactionalId = struct.getOrElse(NULLABLE_TRANSACTIONAL_ID, null);
}
可以看到实际上就是通过 Struct 十分方便地通过字段名获取字段值。
最后,具体请求对象会与其大小保存在 RequestAndSize 中并返回,作为 Request 的成员之一:
private val bodyAndSize: RequestAndSize = context.parseRequest(buffer)
def body[T <: AbstractRequest](implicit classTag: ClassTag[T], nn: NotNothing[T]): T = {
bodyAndSize.request match {
case r: T => r
case r =>
throw new ClassCastException(s"Expected request with type ${classTag.runtimeClass}, but found ${r.getClass}")
}
}
Request 里面还有其他一些方法和成员,目前先不管,后面遇到的时候结合流程一起分析。
响应
简单过了一下“请求”之后,再来简单过一下“响应”。响应由抽象类 Response 及 5 个具体子类组成,先看一下 Response 的定义,比较简单,只是定义了几个成员:
abstract class Response(
// 响应所对应的请求
val request: Request
) {
locally {
val nowNs = Time.SYSTEM.nanoseconds
// 构造响应时就是请求的完成时间
request.responseCompleteTimeNanos = nowNs
if (request.apiLocalCompleteTimeNanos == -1L)
request.apiLocalCompleteTimeNanos = nowNs
}
// 响应由请求的同一个processor线程进行处理
def processor: Int = request.processor
def responseString: Option[String] = Some("")
def onComplete: Option[Send => Unit] = None
override def toString: String
}
然后 5 个子类分别如下:
SendResponse:大多数 Request 处理完后都需要执行一段回调逻辑,SendResponse主要就是为了保存了这段回调逻辑。NoOpResponse:表示不需要做任何事情CloseConnectionResponse:用于出错后需要关闭 TCP 连接StartThrottlingResponse:用于通知 TCP 连接需要限流EndThrottlingResponse:用于结束限流
目前只需要关注 SendResponse,其它几种 Response 类型都只是用作标识而已:
class SendResponse(
request: Request,
// Send接口,包装了需要响应给客户端的数据
// 根据配置,使用不同类型的底层传输、延迟发送等特性
val responseSend: Send,
val responseAsString: Option[String],
// 请求处理完后的回调函数
val onCompleteCallback: Option[Send => Unit]
) extends Response(request) {
override def responseString: Option[String] = responseAsString
override def onComplete: Option[Send => Unit] = onCompleteCallback
override def toString: String =
s"Response(type=Send, request=$request, send=$responseSend, asString=$responseAsString)"
}
RequestChannel
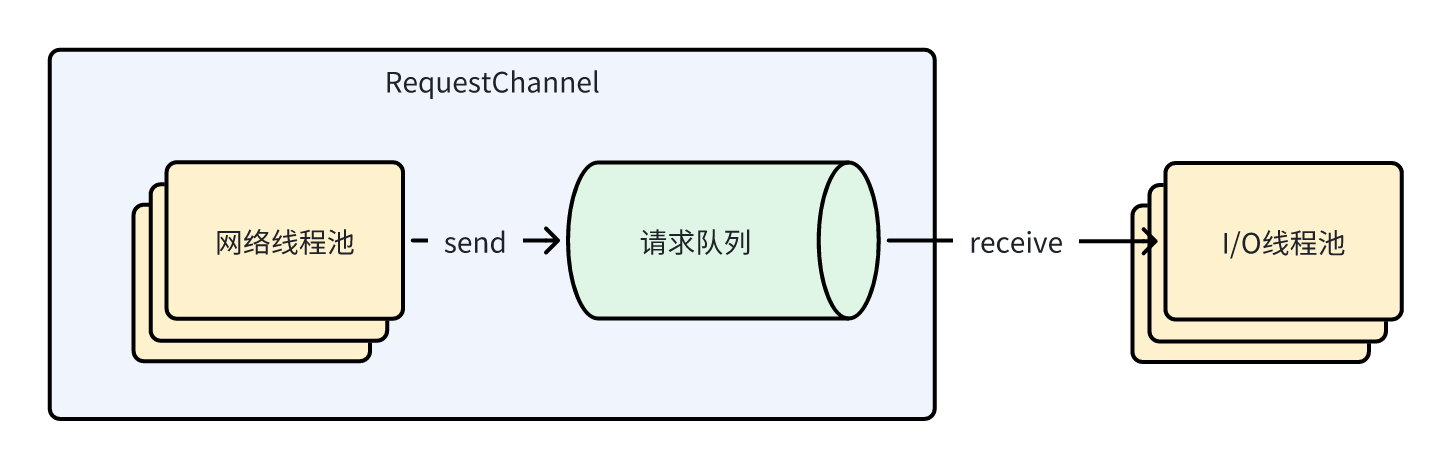
看完上面的 Request 和 Response 的基础知识,就可以开始看 RequestChannel 的实现了。RequestChannel 主要是扮演了请求队列的角色,并且负责管理网络线程池。
首先看下它几个重要成员:
class RequestChannel(val queueSize: Int, val metricNamePrefix : String) extends KafkaMetricsGroup {
import RequestChannel._
// 用于监控指标
val metrics = new RequestChannel.Metrics
// 请求队列
private val requestQueue = new ArrayBlockingQueue[BaseRequest](queueSize)
// 网络线程池
private val processors = new ConcurrentHashMap[Int, Processor]()
// 监控指标名称
val requestQueueSizeMetricName = metricNamePrefix.concat(RequestQueueSizeMetric)
val responseQueueSizeMetricName = metricNamePrefix.concat(ResponseQueueSizeMetric)
}
首先 RequestChannel 混入了 KafkaMetricsGroup 特性,其中封装了很多监控指标相关方法,比如 newGauge 用于创建数值型监控指标,newHistogram 用于创建直方图型监控指标。
然后看到这个类的成员。其中,请求队列 requestQueue 用于暂存 broker 收到的各种请求,作为一个有界阻塞队列,当暂存的请求个数超过 queueSize 时,后续的请求将被阻塞。因此 RequestChannel 相当于提供了请求队列的功能,其 sendRequest 和 receiveRequest 方法也只不过是往队列塞入和取出请求而已:
def sendRequest(request: RequestChannel.Request): Unit = {
requestQueue.put(request)
}
def receiveRequest(timeout: Long): RequestChannel.BaseRequest =
requestQueue.poll(timeout, TimeUnit.MILLISECONDS)
def receiveRequest(): RequestChannel.BaseRequest =
requestQueue.take()
processors 是网络线程池,用一个 map 来管理,其中 key 是 processor 的序号,value 就是 processor。注意这个线程池的大小是可以在运行中通过参数 num.network.threads 动态改变的。
结合上述的请求队列以及网络线程池,他们的关系如图所示:
而对于响应 response,只有 sendResponse 方法。关于 selector 是什么我们后面会说:
def sendResponse(response: RequestChannel.Response): Unit = {
if (isTraceEnabled) {
val requestHeader = response.request.header
// 打印日志
val message = response match {
case sendResponse: SendResponse =>
s"Sending ${requestHeader.apiKey} response to client ${requestHeader.clientId} of ${sendResponse.responseSend.size} bytes."
// ...
}
trace(message)
}
// 获取response对应的processor
val processor = processors.get(response.processor)
if (processor != null) {
processor.enqueueResponse(response)
}
}
// class Processor
private[network] def enqueueResponse(response: RequestChannel.Response): Unit = {
// 将请求放入processor的队列
responseQueue.put(response)
// 唤醒selector去发送响应
wakeup()
}
总结
本篇主要凌乱地过了一遍 RequestChannel.java 这个文件中的请求 Request、响应 Response 以及请求队列 RequestChannel 的代码,没什么干货。
参考
极客时间《Kafka核心源码解读》——胡夕