Note基于开源 kafka 2.5 版本。
如无特殊说明,文中代码片段将删除 debug 信息、异常触发、英文注释等代码,以便观看核心代码。
基于前几篇的 SocketServer 的内容,我们发现漏了一个 KafkaRequestHandler 还没分析(以下简称为 Handler)。因此开始分析请求处理的流程之前我们先来看下这个用于实际处理请求的 Handler。相关代码位于 KafkaRequestHandler.kafka 文件中。
KafkaRequestHandler
Handler 对外是以一整个线程池的形式提供服务的,也就是外界只需要往请求队列中存放请求,线程池中的线程则会获取这些请求并处理。Handler 也叫 I/O 线程,而之前上篇提到的 Processor 和 Acceptor 是网络线程。为什么叫他 I/O 线程呢?很简单,因为 produce、fetch、replica 等请求的处理均涉及磁盘 I/O 。
Handler 相关的类主要有 KafkaRequestHandler(线程)和 KafkaRequestHandlerPool(线程池)两个类。文件中剩下的 BrokerTopicMetrics、BrokerTopicStats 以及 BrokerTopicStats 和监控指标相关,就不说了。
线程
首先来看下线程类 KafkaRequestHandler,这个类负责不断从请求队列获取请求,然后使用 KafkaApis 实际执行该请求的处理逻辑。由于比较简单,我就把整个类都搬上来讲,不单独讲类定义和方法:
class KafkaRequestHandler(
// handler id
id: Int,
brokerId: Int,
val aggregateIdleMeter: Meter,
val totalHandlerThreads: AtomicInteger,
// 请求队列
val requestChannel: RequestChannel,
// 请求处理类
apis: KafkaApis,
time: Time
) extends Runnable with Logging {
this.logIdent = "[Kafka Request Handler " + id + " on Broker " + brokerId + "], "
private val shutdownComplete = new CountDownLatch(1)
@volatile private var stopped = false
def run(): Unit = {
while (!stopped) {
val startSelectTime = time.nanoseconds
// 获取请求
val req = requestChannel.receiveRequest(300)
val endTime = time.nanoseconds
val idleTime = endTime - startSelectTime
aggregateIdleMeter.mark(idleTime / totalHandlerThreads.get)
req match {
case RequestChannel.ShutdownRequest =>
debug(s"Kafka request handler $id on broker $brokerId received shut down command")
// 关闭本Handler
shutdownComplete.countDown()
return
case request: RequestChannel.Request =>
try {
request.requestDequeueTimeNanos = endTime
trace(s"Kafka request handler $id on broker $brokerId handling request $request")
// 处理请求
apis.handle(request)
} catch {
case e: FatalExitError =>
shutdownComplete.countDown()
Exit.exit(e.statusCode)
case e: Throwable => error("Exception when handling request", e)
} finally {
// 释放该请求的缓存
request.releaseBuffer()
}
case null => // continue
}
}
// 关闭本Handler
shutdownComplete.countDown()
}
def stop(): Unit = {
stopped = true
}
def initiateShutdown(): Unit = requestChannel.sendShutdownRequest()
def awaitShutdown(): Unit = shutdownComplete.await()
}
这里的 ShutdownRequest 在kafka源码阅读(5)-请求队列这篇中提到过,用于关闭线程池的时候,优雅关闭里面的线程,调用路径为:
KafkaRequestHandlerPool.shutdown
KafkaRequestHandler.initiateShutdown
RequestChannel.sendShutdownRequest()
requestQueue.put(ShutdownRequest)
KafkaRequestHandler检测到这个ShutdownRequest,并优雅关闭自己
线程池
线程池 KafkaRequestHandlerPool 也很简单,就是用来控制 Handler 的数量而已,broker 启动时线程数量为 numThreads,运行时用户可以通过改变 num.io.threads 参数来调整线程数量,内部会调用 KafkaRequestHandlerPool.resizeThreadPool 方法来增加或减少线程数。
class KafkaRequestHandlerPool(
val brokerId: Int,
// 请求队列
val requestChannel: RequestChannel,
// 请求处理类
val apis: KafkaApis,
time: Time,
// 初始线程数
numThreads: Int,
requestHandlerAvgIdleMetricName: String,
logAndThreadNamePrefix : String
) extends Logging with KafkaMetricsGroup {
// 当前线程数
private val threadPoolSize: AtomicInteger = new AtomicInteger(numThreads)
private val aggregateIdleMeter = newMeter(requestHandlerAvgIdleMetricName, "percent", TimeUnit.NANOSECONDS)
this.logIdent = "[" + logAndThreadNamePrefix + " Kafka Request Handler on Broker " + brokerId + "], "
// 本线程池所有线程
// 下标即为handler id
val runnables = new mutable.ArrayBuffer[KafkaRequestHandler](numThreads)
// 类初始化时,创建并启动numThreads个线程
for (i <- 0 until numThreads) {
createHandler(i)
}
// 创建并启动线程
def createHandler(id: Int): Unit = synchronized {
runnables += new KafkaRequestHandler(id, brokerId, aggregateIdleMeter, threadPoolSize, requestChannel, apis, time)
// 作为守护线程启动
KafkaThread.daemon(logAndThreadNamePrefix + "-kafka-request-handler-" + id, runnables(id)).start()
}
// 调整线程数量
def resizeThreadPool(newSize: Int): Unit = synchronized {
val currentSize = threadPoolSize.get
info(s"Resizing request handler thread pool size from $currentSize to $newSize")
if (newSize > currentSize) {
// 增加线程
for (i <- currentSize until newSize) {
createHandler(i)
}
} else if (newSize < currentSize) {
// 减少线程,调用stop停止并从集合中移除
for (i <- 1 to (currentSize - newSize)) {
runnables.remove(currentSize - i).stop()
}
}
threadPoolSize.set(newSize)
}
// 优雅关闭线程池,即优雅关闭池中所有线程
def shutdown(): Unit = synchronized {
info("shutting down")
for (handler <- runnables)
handler.initiateShutdown()
for (handler <- runnables)
handler.awaitShutdown()
info("shut down completely")
}
}
值得注意的是,上一篇Kafka源码阅读(9)-SocketServer之DataPlane与ControlPlane中提到的 Processor 和 Acceptor 均为非守护线程,而这里的 Handler 是守护线程(程序会等所有非守护线程结束后才退出,但不会管守护线程的死活)。
请求处理全流程
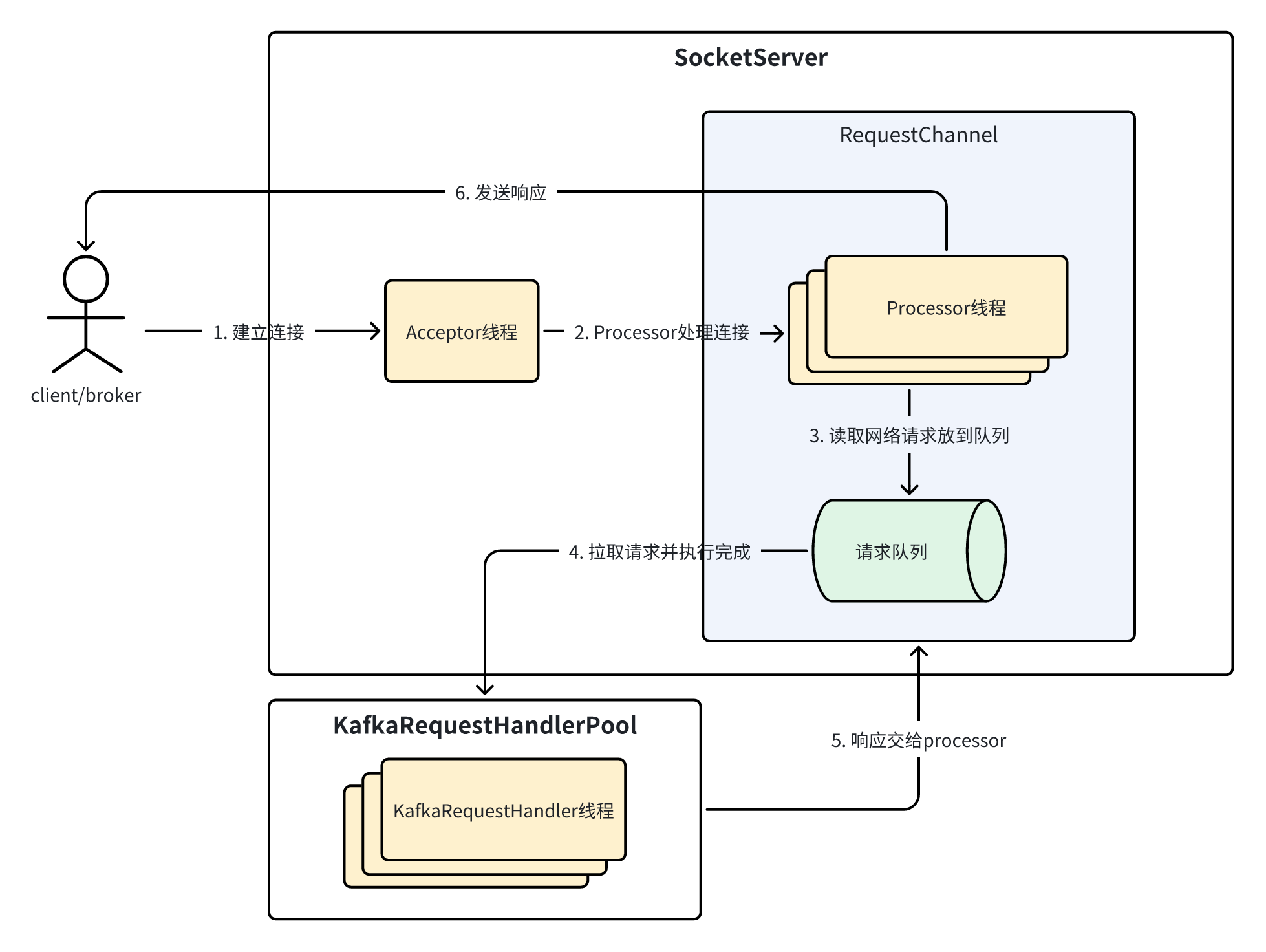
现在再把这张图搬出来,就清晰很多了,因为里面的组件甚至底层的 NIO 相关组件(KSelector、TransportLayer 等)我们全部都介绍过。通过下面几个小节,按顺序介绍一个客户端请求处理的全流程。
Note下面会涉及到的代码片段之前都已经讲过,只是串起来复习一下,所以下面我会精简一下,只提取核心部分代码
客户端建立连接
kafka 客户端与服务端之间基于 TCP 进行通信,发送请求前需要先建立连接,服务端通过 Acceptor 来完成连接的建立。在 Acceptor 的 run 方法中会不断监听新的连接,并分发给 Processor 去处理:
def run(): Unit = {
var currentProcessorIndex = 0
while (isRunning) {
// 获取就绪事件
val ready = nioSelector.select(500)
if (ready > 0) {
val keys = nioSelector.selectedKeys()
val iter = keys.iterator()
// 处理这些OP_ACCEPT事件
while (iter.hasNext && isRunning) {
if (key.isAcceptable) {
// 配置连接,得到SocketChannel
accept(key).foreach { socketChannel =>
var retriesLeft = synchronized(processors.length)
var processor: Processor = null
do {
retriesLeft -= 1
// Acceptor使用round-robin轮询算法,选择下一个processor处理该连接
processor = synchronized {
currentProcessorIndex = currentProcessorIndex % processors.length
processors(currentProcessorIndex)
}
currentProcessorIndex += 1
// 如果processor的内部队列已经满了,继续尝试下一个processor
} while (!assignNewConnection(socketChannel, processor, retriesLeft == 0))
}
}
}
}
}
}
Processor 处理请求
连接建立完成后,将该连接交给 Processor 处理。通过 Processor 的 run 方法我们知道,Processor 是基于 KSelector 去驱动「新连接的注册、接收请求、发送响应」等操作的:
override def run(): Unit = {
while (isRunning) {
try {
// 处理newConnection队列中的新连接
configureNewConnections()
// 处理responseQueue队列中的响应,发送给客户端
processNewResponses()
// 获取新的网络I/O事件
poll()
// 处理请求
processCompletedReceives()
// 处理已完成的响应
processCompletedSends()
// 处理因发送失败导致的客户端连接断开
processDisconnected()
// 检查并关闭超出配额的连接
closeExcessConnections()
} catch {
case e: Throwable => processException("Processor got uncaught exception.", e)
}
}
}
其中,对于请求的处理,之前分析过,首先由 poll 通过底层组件 KSelector 将数据从 socket 缓冲区读到程序中的缓冲区并包装成 NetworkReceive 等待上层处理,上层的 Processor 会调用 processCompletedReceives 来处理这些 NetworkReceive:
private def processCompletedReceives(): Unit = {
// 遍历NetworkReceive
selector.completedReceives.asScala.foreach { receive =>
openOrClosingChannel(receive.source) match {
case Some(channel) =>
// 获取header
val header = RequestHeader.parse(receive.payload)
val nowNanos = time.nanoseconds()
val connectionId = receive.source
// 构建Request
val context = new RequestContext(header, connectionId, channel.socketAddress,
channel.principal, listenerName, securityProtocol,
channel.channelMetadataRegistry.clientInformation)
val req = new RequestChannel.Request(processor = id, context = context,
startTimeNanos = nowNanos, memoryPool, receive.payload, requestChannel.metrics)
// 将Request发送到RequestChannel待处理
requestChannel.sendRequest(req)
// 将通道静默,等待请求处理完毕后再继续接收新的请求,底层实现是注销OP_READ
selector.mute(connectionId)
handleChannelMuteEvent(connectionId, ChannelMuteEvent.REQUEST_RECEIVED)
case None =>
throw new IllegalStateException(s"Channel ${receive.source} removed from selector before processing completed receive")
}
}
Handler 执行请求处理逻辑
上一步中,Processor 将 NetworkReceive 转换成了 Request 放到请求队列中等待处理,下一步就是 Handler 从请求队列中获取请求并借助 KafkaApis 执行处理逻辑:
def run(): Unit = {
while (!stopped) {
// 从请求队列获取请求
val req = requestChannel.receiveRequest(300)
req match {
case RequestChannel.ShutdownRequest =>
// ...
case request: RequestChannel.Request =>
try {
request.requestDequeueTimeNanos = endTime
trace(s"Kafka request handler $id on broker $brokerId handling request $request")
// 执行请求处理逻辑
apis.handle(request)
} catch {
// ...
} finally {
// 释放请求的缓存
request.releaseBuffer()
}
case null => // continue
}
}
}
KafkaApis 内部会根据请求类型来调用相应的 handleXXXRequest 方法来处理,比如我们挑个简单的请求类型来举例,LIST_GROUPS 类型的 API 请求将会调用 handleListGroupsRequest 进行处理,该 API 的功能是列出集群中消费者组的信息:
def handleListGroupsRequest(request: RequestChannel.Request): Unit = {
// 获取所有消费者组的信息
val (error, groups) = groupCoordinator.handleListGroups()
// 如果客户端拥有集群的描述权限
if (authorize(request, DESCRIBE, CLUSTER, CLUSTER_NAME))
// 将所有消费者组信息返回给客户端
sendResponseMaybeThrottle(request, requestThrottleMs =>
new ListGroupsResponse(new ListGroupsResponseData()
.setErrorCode(error.code)
.setGroups(groups.map { group => new ListGroupsResponseData.ListedGroup()
.setGroupId(group.groupId)
.setProtocolType(group.protocolType)}.asJava
)
.setThrottleTimeMs(requestThrottleMs)
))
else {
// 否则,过滤掉那些没有描述权限的消费者组
val filteredGroups = groups.filter(group => authorize(request, DESCRIBE, GROUP, group.groupId))
// 将有描述权限的消费者组信息返回给客户端
sendResponseMaybeThrottle(request, requestThrottleMs =>
new ListGroupsResponse(new ListGroupsResponseData()
.setErrorCode(error.code)
.setGroups(filteredGroups.map { group => new ListGroupsResponseData.ListedGroup()
.setGroupId(group.groupId)
.setProtocolType(group.protocolType)}.asJava
)
.setThrottleTimeMs(requestThrottleMs)
))
}
}
请求处理完成后,最终会调用 processor.enqueueResponse(response) 将响应发送到负责该连接的 Processor 的响应队列中待处理。因此从执行请求逻辑到得到响应的调用路径是:
KafkaRequestHandler.run
KafkaApis.handle
KafkaApis.handleXXXRequest
KafkaApis.sendResponse
RequestChannel.sendResponse(response)
Processor.enqueueResponse(response)
Processor 处理响应
在得到响应的最后一步 Processor.enqueueResponse(response) 中,会调用 wakeup 唤醒 selector:
private[network] def enqueueResponse(response: RequestChannel.Response): Unit = {
responseQueue.put(response)
wakeup()
}
此举的目的是让 poll 调用快速返回,并来到下一轮循环中调用 processNewResponses 及时队列中的待处理响应:
private def processNewResponses(): Unit = {
var currentResponse: RequestChannel.Response = null
// 获取队列中的待处理响应
while ({currentResponse = dequeueResponse(); currentResponse != null}) {
currentResponse match {
case response: SendResponse =>
// 发送响应,实际上是注册OP_WRITE事件
sendResponse(response, response.responseSend)
case // ...
}
}
}
注意这里的处理响应只是保存了 NetworkSend 并注册 OP_WRITE 事件,等到下一轮 poll 发现 OP_WRITE 就绪后才会将这些响应发送给客户端,发送完毕后 Processor 会调用 processCompletedSends 进行收尾工作:
private def processCompletedSends(): Unit = {
// 遍历NetworkSend
selector.completedSends.asScala.foreach { send =>
// 将该响应从inflightResponses中移除
val response = inflightResponses.remove(send.destination).getOrElse {
throw new IllegalStateException(s"Send for ${send.destination} completed, but not in `inflightResponses`")
}
// 执行响应完成后的回调
response.onComplete.foreach(onComplete => onComplete(send))
// 通道取消静默
handleChannelMuteEvent(send.destination, ChannelMuteEvent.RESPONSE_SENT)
tryUnmuteChannel(send.destination)
}
selector.clearCompletedSends()
}
总结
本篇是 SocketServer 组件的收尾篇,主要介绍了请求处理相关的最后一个组件,即负责执行请求处理逻辑的 KafkaRequestHandler,最后再快速串了一下客户端从连接建立、请求接收和处理,最后到响应返回的全流程,因为除了掌握各个组件的实现细节外,整体的流程和架构也是必须要清楚的。
参考
极客时间《Kafka核心源码解读》——胡夕