gRPC介绍
gRPC 是一种由 Google 开发的高性能远程过程调用(RPC)框架,适用于分布式系统间的通信。它基于 HTTP/2 进行传输,使用 Protocol Buffers 进行序列化,提供跨平台的兼容性。gRPC 的核心理念是让客户端像调用本地函数一样调用远程服务,简化服务间的调用流程。
通过编写与具体编程语言无关的 IDL (默认是 protobuf) 来定义 RPC 方法,gRPC 框架就会生成语言相关的客户端/服务端代码。
HTTP/2介绍
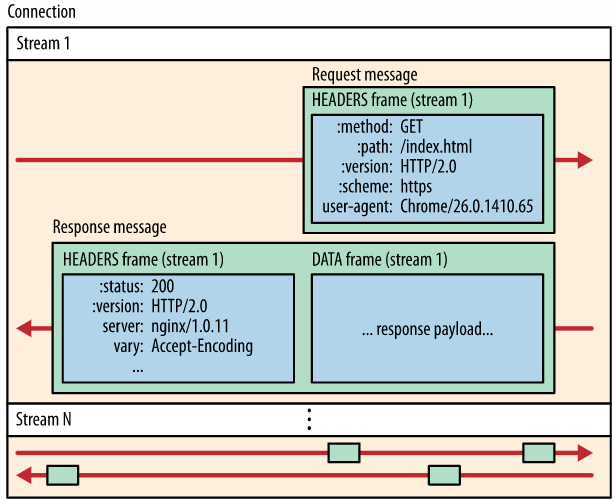
相比http1,具有更高的传输效率(多路复用:在同一个链连接上同时处理多个请求),更低的延迟(服务端推送,减少请求数量、简化header大小)、带宽利用率更高(头部压缩、数据流优先)、更安全(基于tls)。
http2具体特性有:
- 帧、消息、流:帧是小通信数据单元;消息由一个或多个帧组成。例如请求的消息和响应的消息;一个连接中包含多个流,每个流包含多个帧。帧通过流id进行标识属于哪个流
- 二进制分帧:每个消息由若干个帧组成,帧是最小传输单位,并且原来基于文本编码变成基于二进制,进一步减小帧大小
- 压缩header
- 多路复用:即在同一连接中的多个stream的传输互不影响
- 服务端推送
- 流量控制和资源优先级:流量控制以有效利用多路复用机制,确保只有接收者使用的数据会被传输。优先级机制可以确保重要的资源被优先传输。
启动服务端
通过官方的 helloworld 例子可以看到,服务端的启动分为三步:
- 创建gRPC的Server
- 将业务handler注册到Server
- 调用Server.Serve在端口上进行监听
第一步没什么好说的,注意下第二步注册进去的东西:
// 注册进去的ServiceDesc
var Greeter_ServiceDesc = grpc.ServiceDesc{
ServiceName: "helloworld.Greeter",
HandlerType: (*GreeterServer)(nil),
Methods: []grpc.MethodDesc{
{
MethodName: "SayHello",
Handler: _Greeter_SayHello_Handler,
},
},
Streams: []grpc.StreamDesc{},
Metadata: "helloworld/helloworld.proto",
}
// Method对应的handler
func _Greeter_SayHello_Handler(srv interface{}, ctx context.Context, dec func(interface{}) error, interceptor grpc.UnaryServerInterceptor) (interface{}, error) {
in := new(HelloRequest)
if err := dec(in); err != nil {
return nil, err
}
if interceptor == nil {
return srv.(GreeterServer).SayHello(ctx, in)
}
info := &grpc.UnaryServerInfo{
Server: srv,
FullMethod: Greeter_SayHello_FullMethodName,
}
handler := func(ctx context.Context, req interface{}) (interface{}, error) {
return srv.(GreeterServer).SayHello(ctx, req.(*HelloRequest))
}
return interceptor(ctx, in, info, handler)
}
前两步比较简单,再来看第三步的如何建立连接并进行处理。类似标准库http的ListenAndServe,本质上就是创建一个死循环等待有新的连接到来,然后开新的goroutine去处理这个连接上的读写事件:
func (s *Server) Serve(lis net.Listener) error {
...
// 优雅停止相关
s.serveWG.Add(1)
defer func() {
s.serveWG.Done()
if s.quit.HasFired() {
// Stop or GracefulStop called; block until done and return nil.
<-s.done.Done()
}
}()
// 初始化listenerSocket
ls := &listenSocket{
Listener: lis,
channelz: channelz.RegisterSocket(&channelz.Socket{
SocketType: channelz.SocketTypeListen,
Parent: s.channelz,
RefName: lis.Addr().String(),
LocalAddr: lis.Addr(),
SocketOptions: channelz.GetSocketOption(lis)},
),
}
s.lis[ls] = true
...
channelz.Info(logger, ls.channelz, "ListenSocket created")
var tempDelay time.Duration // how long to sleep on accept failure
for {
// 建立新连接
rawConn, err := lis.Accept()
// 处理连接错误
if err != nil {
if ne, ok := err.(interface {
Temporary() bool
}); ok && ne.Temporary() {
// 偶发性错误,continue
}
s.mu.Lock()
s.printf("done serving; Accept = %v", err)
s.mu.Unlock()
if s.quit.HasFired() {
return nil
}
// 返回错误
return err
}
tempDelay = 0
s.serveWG.Add(1)
// 开新的goroutine去处理这个连接
go func() {
s.handleRawConn(lis.Addr().String(), rawConn)
s.serveWG.Done()
}()
}
}
其中处理连接的代码在handleRawConn中:
func (s *Server) handleRawConn(lisAddr string, rawConn net.Conn) {
...
// 创建http2 transport,http2也是gRPC唯一的ServerTransport
st := s.newHTTP2Transport(rawConn)
rawConn.SetDeadline(time.Time{})
if st == nil {
return
}
// ?
if cc, ok := rawConn.(interface {
PassServerTransport(transport.ServerTransport)
}); ok {
cc.PassServerTransport(st)
}
// 将该transport保存到s中
if !s.addConn(lisAddr, st) {
return
}
// 开启新协程去处理连接
go func() {
s.serveStreams(context.Background(), st, rawConn)
s.removeConn(lisAddr, st)
}()
}
至此,各个步骤都十分明了以及常规,下面继续深入分析Server如何处理每个连接。(最后两行,暂时不理解为什么要多开一个协程而不是在当前协程进行处理,不过问题不大)
处理连接
func (s *Server) serveStreams(ctx context.Context, st transport.ServerTransport, rawConn net.Conn) {
ctx = transport.SetConnection(ctx, rawConn)
ctx = peer.NewContext(ctx, st.Peer())
// stats
for _, sh := range s.opts.statsHandlers {
ctx = sh.TagConn(ctx, &stats.ConnTagInfo{
RemoteAddr: st.Peer().Addr,
LocalAddr: st.Peer().LocalAddr,
})
sh.HandleConn(ctx, &stats.ConnBegin{})
}
defer func() {
st.Close(errors.New("finished serving streams for the server transport"))
for _, sh := range s.opts.statsHandlers {
sh.HandleConn(ctx, &stats.ConnEnd{})
}
}()
// 信号量限制处理stream的最大并发度
streamQuota := newHandlerQuota(s.opts.maxConcurrentStreams)
// transport将连接封装为一个个stream进行处理
st.HandleStreams(ctx, func(stream *transport.ServerStream) {
s.handlersWG.Add(1)
streamQuota.acquire()
f := func() {
defer streamQuota.release()
defer s.handlersWG.Done()
// 处理stream
s.handleStream(st, stream)
}
// 优先让worker来处理这个stream
if s.opts.numServerWorkers > 0 {
select {
case s.serverWorkerChannel <- f:
return
default:
}
}
// 如果所有的worker都在忙,那么就新开一个协程来处理这个stream
go f()
})
}
我们先忽略transport如何连接封装为stream,我们把stream看成是连接就行了。另外暂时不管worker是什么。下面直接分析handleStream如何处理stream
处理流
以下直接省略了不重要的代码分支,以便不用费时间观看这些垃圾细节(比如pos=-1,找不到斜杠则关闭流之类的处理)
func (s *Server) handleStream(t transport.ServerTransport, stream *transport.ServerStream) {
// 获取service名和method名
sm := stream.Method()
pos := strings.LastIndex(sm, "/")
service := sm[:pos]
method := sm[pos+1:]
// 查询service
srv, knownService := s.services[service]
if knownService {
// 查询unery-method
if md, ok := srv.methods[method]; ok {
// 处理unary-method
s.processUnaryRPC(ctx, t, stream, srv, md, ti)
return
}
// 查询streaming-method
if sd, ok := srv.streams[method]; ok {
// 处理streaming-method
s.processStreamingRPC(ctx, t, stream, srv, sd, ti)
return
}
}
// 调用用户自定义的处理器
if unknownDesc := s.opts.unknownStreamDesc; unknownDesc != nil {
s.processStreamingRPC(ctx, t, stream, nil, unknownDesc, ti)
return
}
// 即找不到服务/方法,也没有用户自定义处理器,给客户端返回错误
...
}
其实很简单,所谓查询的service/method其实就是在创建Server时由用户注册进来的那些信息。
我们继续分析最简单的unary-rpc的处理函数processUnaryRPC,这个函数挺长的,不过大多数代码都与tracing, logging, stats相关,不影响主流程分析。但也看得出来一个框架不能仅仅是完成功能,可观测性和后续的可维护性也同样重要:
func (s *Server) processUnaryRPC(ctx context.Context, t transport.ServerTransport, stream *transport.ServerStream, info *serviceInfo, md *MethodDesc, trInfo *traceInfo) (err error) {
// tracing, logging
...
// 设置解码器和编码器
...
// 从stream读取数据并解码
// 这里的解码指的是将payload从数据帧从取出,用BufferSlice保存
d, err := recvAndDecompress(&parser{r: stream, bufferPool: s.opts.bufferPool}, stream, dc, s.opts.maxReceiveMessageSize, payInfo, decomp, true)
// decode function
// 这里的解码指的是将payload反序列化成具体的对象
df := func(v any) error {
if err := s.getCodec(stream.ContentSubtype()).Unmarshal(d, v); err != nil {
return status.Errorf(codes.Internal, "grpc: error unmarshalling request: %v", err)
}
// tracing, stats, logging
...
return nil
}
ctx = NewContextWithServerTransportStream(ctx, stream)
// 调用用户注册进来的Method对应的Handler,即处理请求,返回响应
// 可以看到,返回的错误命名为appErr,属于业务层抛出的错误
reply, appErr := md.Handler(info.serviceImpl, ctx, df, s.opts.unaryInt)
if appErr != nil {
appStatus, ok := status.FromError(appErr)
...
if e := t.WriteStatus(stream, appStatus); e != nil {
channelz.Warningf(logger, s.channelz, "grpc: Server.processUnaryRPC failed to write status: %v", e)
}
...
return appErr
}
if trInfo != nil {
trInfo.tr.LazyLog(stringer("OK"), false)
}
opts := &transport.Options{Last: true}
// 发送响应
if err := s.sendResponse(ctx, t, stream, reply, cp, opts, comp); err != nil {
...
}
...
return t.WriteStatus(stream, statusOK)
}
多路复用
gRPC的多路复用实际上就是HTTP2的多路复用,即在同一连接上可以同时处理多个不同的stream。之前分析到handleStream这个函数的时候,有没有想过这里的stream是怎么来的呢,答案就藏在st.HandleStreams中:通过传入处理stream的回调函数,由transport负责解析出这些stream之后,封装成ServerStream,调用回调函数交给Server进行处理。
在开始进入HandleStream方法之前,还需要先了解下controlBuffer和loopyWriter(简称为cb和loopy),cb是transport中的其中一个成员变量,负责给loopy传递数据帧和控制帧:
type http2Server struct {
// controlBuf delivers all the control related tasks (e.g., window
// updates, reset streams, and various settings) to the controller.
controlBuf *controlBuffer
}
这里说的帧,要跟http2的帧区别开来,即使某些cb帧可能对应http2的帧类型,但cb帧最终目的还是控制loopy的状态和行为,而不是直接发送到网络上。如图有14种cb帧,他们都实现了cbItem接口:
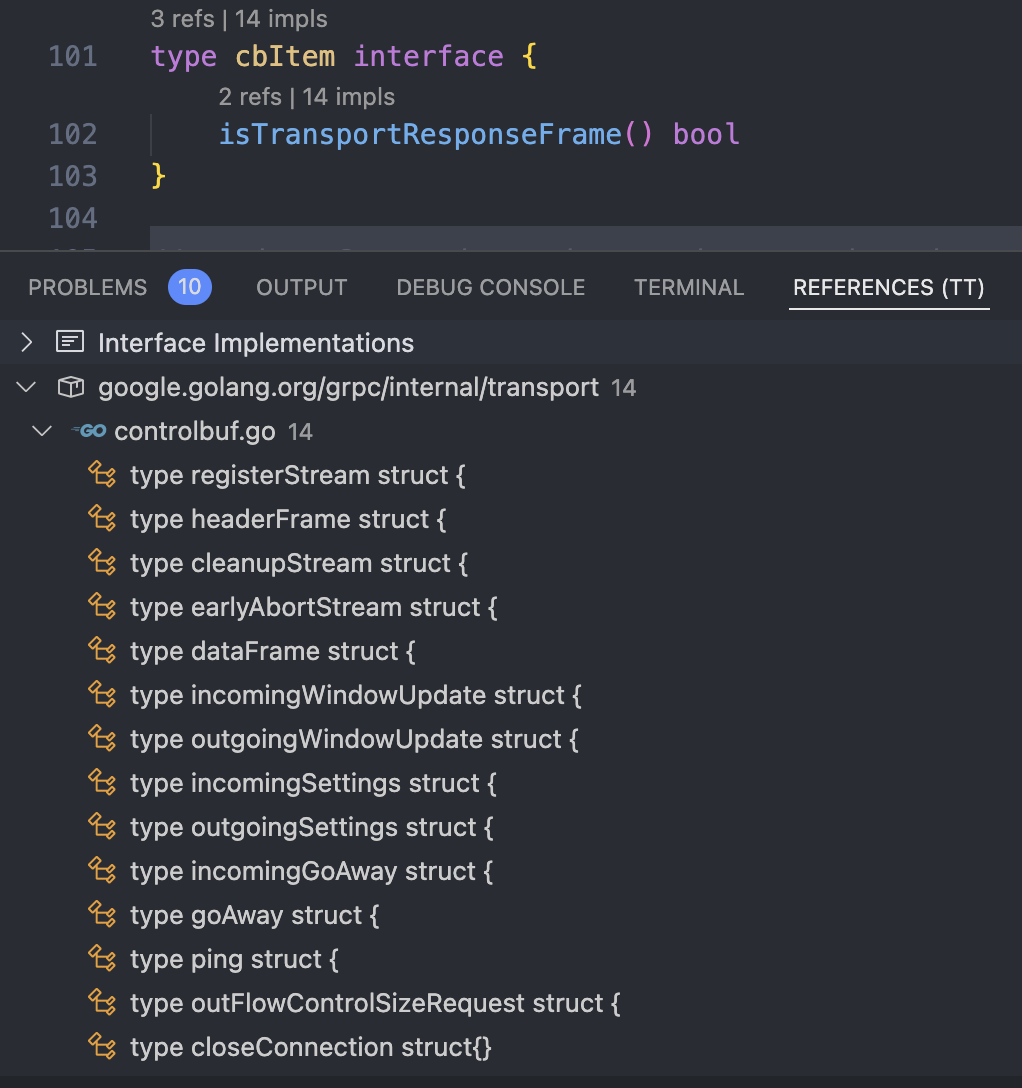
loopy负责不断从cb中读取数据帧和控制帧,维护待写入数据的stream的状态、负责数据写入连接中(发送数据)。loopy在transport初始化的时候就开始运行:
// 创建loopy
func NewServerTransport(conn net.Conn, config *ServerConfig) (_ ServerTransport, err error) {
go func() {
t.loopy = newLoopyWriter(serverSide, t.framer, t.controlBuf, t.bdpEst, t.conn, t.logger, t.outgoingGoAwayHandler, t.bufferPool)
err := t.loopy.run()
...
}()
}
// 运行loopy
func (l *loopyWriter) run() (err error) {
defer func() {
if l.logger.V(logLevel) {
l.logger.Infof("loopyWriter exiting with error: %v", err)
}
// 如果不是IO错误,冲刷缓冲区数据
if !isIOError(err) {
l.framer.writer.Flush()
}
// 关闭cb
l.cbuf.finish()
}()
// 循环处理帧
for {
// 获取一个cb帧并处理(阻塞)
it, err := l.cbuf.get(true)
if err != nil {
return err
}
if err = l.handle(it); err != nil {
return err
}
// 处理发送数据
if _, err = l.processData(); err != nil {
return err
}
gosched := true
hasdata:
// 循环处理数据
for {
// 获取下一个cb帧并处理(非阻塞)
it, err := l.cbuf.get(false)
if err != nil {
return err
}
if it != nil {
if err = l.handle(it); err != nil {
return err
}
if _, err = l.processData(); err != nil {
return err
}
continue hasdata
}
isEmpty, err := l.processData()
if err != nil {
return err
}
if !isEmpty {
continue hasdata
}
// 为了减少IO次数,当第一次读到的数据不满一批时,尝试yield等待更多数据进来
// 下一次还是不满的话,就不管了,直接冲刷缓冲区
if gosched {
gosched = false
if l.framer.writer.offset < minBatchSize {
runtime.Gosched()
continue hasdata
}
}
l.framer.writer.Flush()
break hasdata
}
}
}
总而言之cb+loopy类似一个小型的mq+consumer,不仅规范了流级别的传输控制,还将传输控制与传输内容本身进行了解耦。关于cb和loopy的内部实现我们暂时不关心。
很快我们会在HandleStreams中遇到第一个cb帧。下面回到HandleStreams中接着分析:
func (t *http2Server) HandleStreams(ctx context.Context, handle func(*ServerStream)) {
defer func() {
close(t.readerDone)
<-t.loopyWriterDone
}()
// 循环读取帧
for {
// 限制正在排队的cb响应帧个数,比如incomingSettings、cleanupStreams
t.controlBuf.throttle()
// 读取HTTP2帧
frame, err := t.framer.fr.ReadFrame()
// 记录最后一次读操作,与keepalive相关
atomic.StoreInt64(&t.lastRead, time.Now().UnixNano())
if err != nil {
if se, ok := err.(http2.StreamError); ok {
// 如果是该stream错误,则直接关闭这个stream,不影响其它stream
if t.logger.V(logLevel) {
t.logger.Warningf("Encountered http2.StreamError: %v", se)
}
t.mu.Lock()
s := t.activeStreams[se.StreamID]
t.mu.Unlock()
if s != nil {
// 如果stream不为空,清空transport中维护的这个stream
// 然后cleanupStream
t.closeStream(s, true, se.Code, false)
} else {
// transport没有维护这个stream,直接cleanupStream
t.controlBuf.put(&cleanupStream{
streamID: se.StreamID,
rst: true,
rstCode: se.Code,
onWrite: func() {},
})
}
continue
}
// 对于其它错误,直接强行关闭连接
t.Close(err)
return
}
// 处理不同类型的帧
switch frame := frame.(type) {
case *http2.MetaHeadersFrame:
if err := t.operateHeaders(ctx, frame, handle); err != nil {
// 处理header失败直接发送GoAway优雅关闭连接
t.controlBuf.put(&goAway{
code: http2.ErrCodeProtocol,
debugData: []byte(err.Error()),
closeConn: err,
})
continue
}
case *http2.DataFrame:
t.handleData(frame)
case *http2.RSTStreamFrame:
t.handleRSTStream(frame)
case *http2.SettingsFrame:
t.handleSettings(frame)
case *http2.PingFrame:
t.handlePing(frame)
case *http2.WindowUpdateFrame:
t.handleWindowUpdate(frame)
case *http2.GoAwayFrame:
// TODO: Handle GoAway from the client appropriately.
default:
if t.logger.V(logLevel) {
t.logger.Infof("Received unsupported frame type %T", frame)
}
}
}
}
(暂时不清楚为什么要做throttle限流,而且只针对响应帧进行限流,那么不做这个限流会有什么影响吗?)
上面出现的两个cb帧:
- cleanupStream:清空cb中维护的这个stream,如果rst=true,还会RST帧告知对方流被重置
- goAway:当解析协议失败,发送GoAway告知对方优雅关闭连接
HandleStream传入的handle,是在处理Header帧的时候使用的:
func (t *http2Server) operateHeaders(ctx context.Context, frame *http2.MetaHeadersFrame, handle func(*ServerStream)) error {
// Header被截断,无法处理,直接RST
if frame.Truncated {
t.controlBuf.put(&cleanupStream{
streamID: streamID,
rst: true,
rstCode: http2.ErrCodeFrameSize,
onWrite: func() {},
})
return nil
}
// 客户端streamID是奇数,服务端的是偶数,并且双方的streamID都是递增的
if streamID%2 != 1 || streamID <= t.maxStreamID {
...
}
t.maxStreamID = streamID
// 创建ServerStream,维护服务端的stream
buf := newRecvBuffer()
s := &ServerStream{
...
}
// 根据协议,处理所有相关headers
// 如果遇到协议错误、header缺失、header解析失败等错误,则向客户端发送错误帧
for _, hf := range frame.Fields {
switch hf.Name {
case "content-type":
...
}
}
// 保存metadata到context里
...
// 确认是否能接受这个stream(比如transport已关闭、超过stream的数量限制等都会被拒绝)
if t.state != reachable {
...
}
if uint32(len(t.activeStreams)) >= t.maxStreams {
...
}
// grpc规定使用HTTP2的POST方法进行数据传输
if httpMethod != http.MethodPost {
...
}
// InTapHandle,是每个新stream建立时的回调,比如可以用来做限流
// 官方将其定为experimental,因此不过多介绍
if t.inTapHandle != nil {
var err error
if s.ctx, err = t.inTapHandle(s.ctx, &tap.Info{FullMethodName: s.method, Header: mdata}); err != nil {
...
}
}
// 保存该stream
t.activeStreams[streamID] = s
// 流量控制的相关回调,当从stream读取数据时触发
s.requestRead = func(n int) {
t.adjustWindow(s, uint32(n))
}
s.ctxDone = s.ctx.Done()
s.wq = newWriteQuota(defaultWriteQuota, s.ctxDone)
s.trReader = &transportReader{
reader: &recvBufferReader{
ctx: s.ctx,
ctxDone: s.ctxDone,
recv: s.buf,
},
windowHandler: func(n int) {
t.updateWindow(s, uint32(n))
},
}
// 将stream注册到loopy中
t.controlBuf.put(®isterStream{
streamID: s.id,
wq: s.wq,
})
// 调用我们的回调函数,对应“流处理”那个小节所做的事情
handle(s)
return nil
}
总结
至此我们大概梳理了一下整个服务端数据流转的闭环:
- 建立连接
- 处理连接
- 处理流(多路复用,一条连接上有多个流)
- 调用业务逻辑进行Req/Reply处理
静态代码都过了一遍,然后再打个断点,看一下在一次unary-rpc的调用过程中,服务端都收到了什么帧。我们在HandleStreams方法中,给不同类型的帧都打上断点,运行发现按照顺序收到的帧是:
- SettingsFrame(作为通信序言,协调后续发送相关的设置)
- MetaHeadersFrame(请求头)
- DataFrame(数据)
- PingFrame(这个是ping ack,服务端处理完这个帧并响应后,客户端那边就显示调用完成了)
- WindowUpdateFrame(用于更新服务端的发送窗口大小)
- PingFrame(客户端最后还会再ping一下)
另外,第一个PingFrame不仅仅代表一个ping ack,还与流量控制有关,具体参考这篇官方博客。大概意思就是这个ping会用来检测网络情况并动态更新发送窗口大小:服务端会首先在开始接收数据帧的时候发一个BDP ping(带宽时延积ping),当数据帧接收完毕后收到对方的ping ack,计算出这段时间内的BDP,以此来调整窗口大小。
最后再简单看一下请求头帧MetaHeadersFrame,包含了哪些header
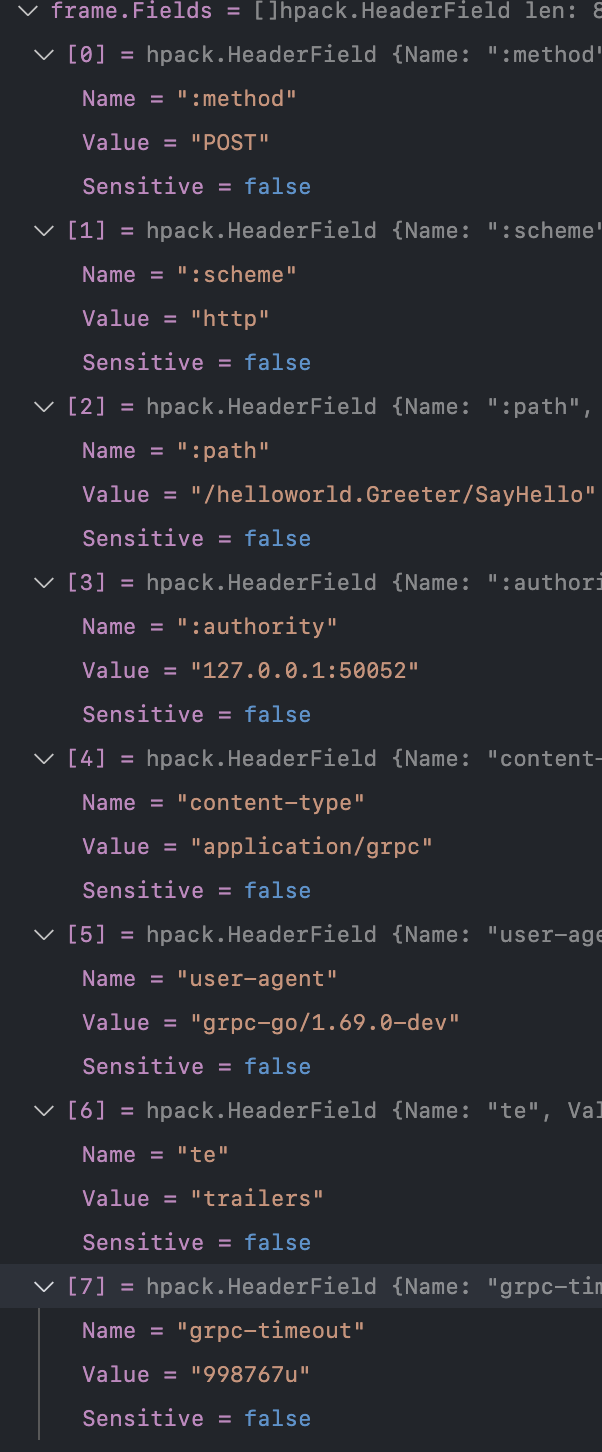
可以看到有我们熟悉的:method,说明grpc基于http的POST方法、:path包含了service的名字和方法名并使用"/“分割、content-type是grpc、timeout是客户端调用rpc时传入context的超时时间,大概是1s。
参考
https://github.com/grpc/grpc/blob/master/CONCEPTS.md
https://github.com/lubanproj/grpc-read/blob/master/1-grpc%20concepts%20%26%20http2.md