Note本文基于go1.21.2,不同版本的go可能会有差异。文中部分代码会由于不是知识点强相关而省略,但被忽略的每行代码或多或少都有它们实际的用处,甚至可能不宜删除,欢迎指出
Tip分析底层的相关的代码时,往往会由于平台架构而带来代码上的差异,比如我机器是darwin/arm64,使用vscode查看代码,而且我希望基于linux/amd64来看代码,可以在
.vscode/settings.json中设置GOOS和GOARCH:{ "go.toolsEnvVars": { "GOOS": "linux", "GOARCH": "amd64" } }这样我在打开平台相关的代码文件比如
os_linux.go时,go插件就能支持代码跳转
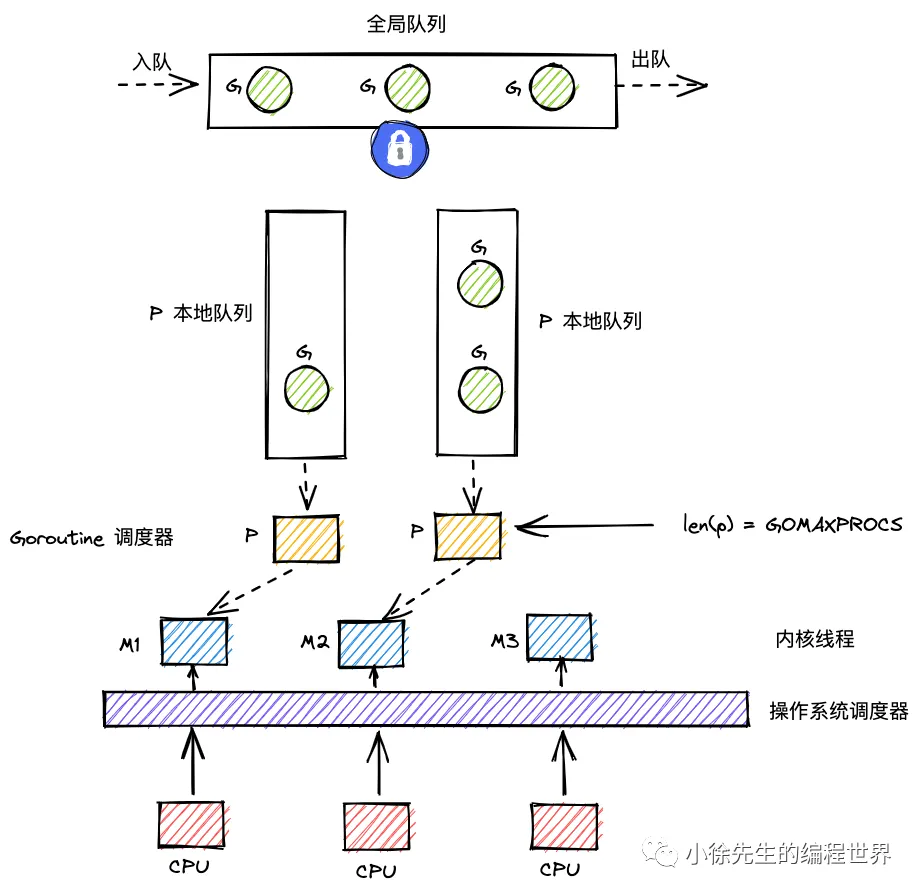
go调度器发展历史
go1.0.1后,2012 年 Google 的工程师 Dmitry Vyukov 提出GMP模型以及基于P的work-stealing来改进原来的G-M多线程模型。
但就算有了GMP模型,程序依然要依靠G主动让出CPU才能触发调度(正常结束或者runtime.GoSched)
go1.2引入基于协作的抢占式调度来解决:
- G长时间占用导致其他G饥饿
- 垃圾回收STW时间过长,导致整个程序无法工作
编译器会在函数调用前插入runtime.morestack,这个函数可能会调用runtime.newstack,其中会检查G的stackguard0为StackPreempt的话,让出当前线程。因此基于协作的抢占调度为:
- 编译器在函数调用前插入
runtime.morestack - 运行时会在STW或者系统监控发现G连续运行超过10ms时发出抢占请求,将G的
stackguard0设置为StackPreempt - 发生函数调用时
runtime.morestack中检查是否有抢占请求并让出线程
go1.14引入基于异步信号的真抢占式调度,目前只有STW和栈扫描会发起抢占信号:
- 程序启动时注册
SIGURG信号的处理函数runtime.doSigPreempt - 在GC和栈扫描的时候将处于
_Grunnable状态的G标记成可抢占并向线程发送SIGURG信号 runtime.doSigPreempt将修改pc跳转回用户态执行runtime.asyncPreemptruntime.asyncPreempt保存用户寄存器,将当前G的状态为_Gpreempted,调用runtime.schedule让G陷入休眠并让出线程,调度器调度其他G运行
bootstrap
golang程序代码的运行离不开进程、线程以及goroutine这些概念,而无论是什么程序都从第一行代码/指令开始执行,所以我打算从整个程序的第一行汇编指令的执行开始说起,另外我们经常说到的g0、m0其实是在入口汇编代码中初始化的,所以更有必要从头讲起。不过不会太深入,因为很多知识我也只是有个概念,欢迎指出谬误。
每个平台架构的代码会有区别,我这边的环境为GOOS=linux,GOARCH=arm64,不同架构的运行流程大同小异。
参考某位博主的博客,了解到了delve这个好用的东西,在我看来delve是用于go的gdb调试器,可以汇编指令单步调试。下面用它来执行一把这个hello world程序,看看程序的入口代码:
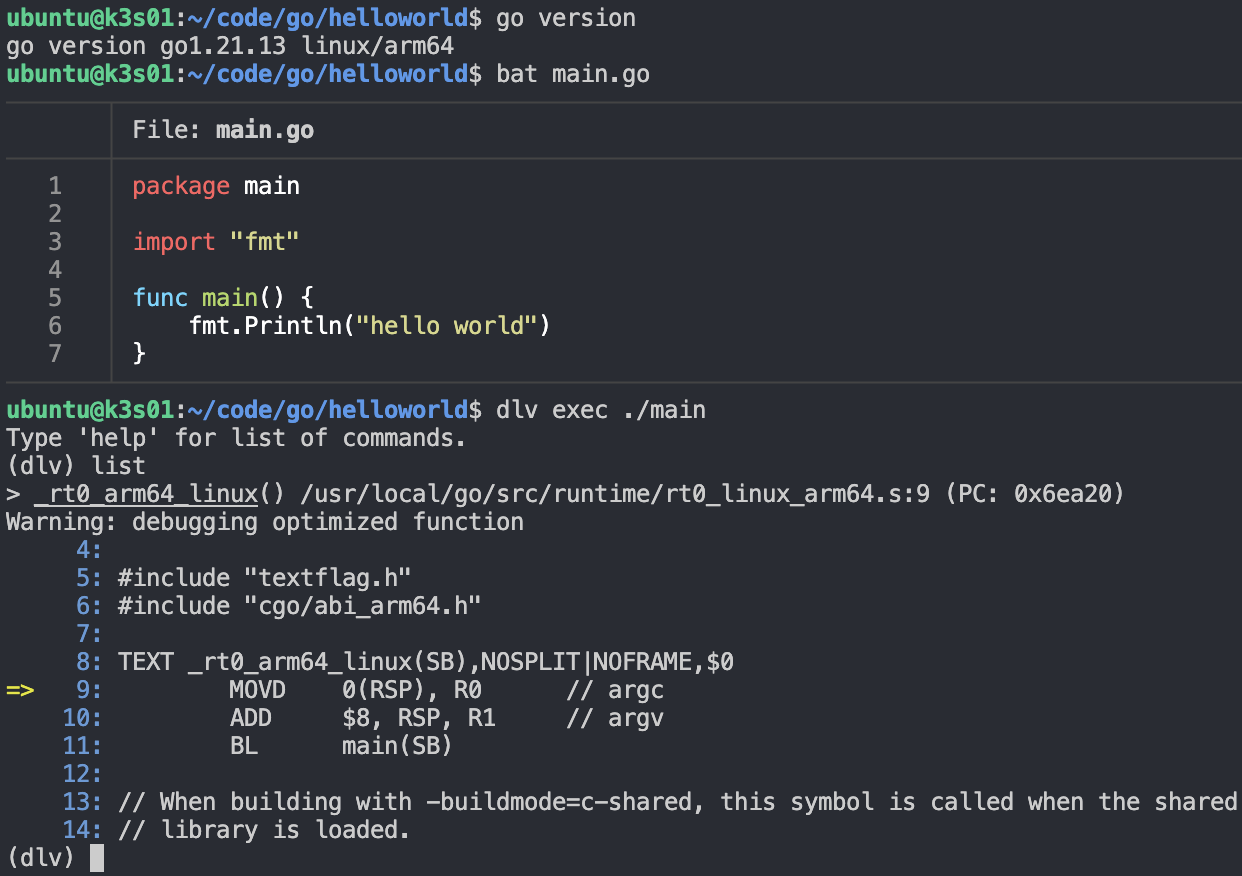
可以看到入口函数_rt0_arm64_linux其实是直接去到了main函数(汇编中定义的main函数,如果是go中的main通常会加包名前缀runtime·,比如runtime.main在汇编中是runtime·main):
TEXT main(SB),NOSPLIT|NOFRAME,$0
; 跳转到runtime·rt0_go代码段
MOVD $runtime·rt0_go(SB), R2
BL (R2)
exit:
MOVD $0, R0
MOVD $94, R8 // sys_exit
SVC
B exit
{: file=‘runtime/rt0_linux_arm64.s’}
可以看到这个函数也只是跳到了另一个函数runtime·rt0_go,返回之后调用了系统调用sys_exit退出程序。runtime·rt0_go函数在asm_arm64.s文件中,这个函数还涉及到启动参数的初始化:
TEXT runtime·rt0_go(SB),NOSPLIT|TOPFRAME,$0
; 将启动参数放到栈中,下面会拿出来用
SUB $32, RSP
MOVW R0, 8(RSP) // argc
MOVD R1, 16(RSP) // argv
...
; 初始化g0,对应proc.go中定义的g0变量
MOVD $runtime·g0(SB), g
...
; 初始化m0,对应proc.go中的m0变量
MOVD $runtime·m0(SB), R0
; 绑定g0和m0
MOVD g, m_g0(R0)
MOVD R0, g_m(g)
BL runtime·check(SB)
; 调用runtime.args,保存启动参数到argc和argv变量中
MOVW 8(RSP), R0 // copy argc
MOVW R0, -8(RSP)
MOVD 16(RSP), R0 // copy argv
MOVD R0, 0(RSP)
BL runtime·args(SB)
; 调用runtime.osinit初始化ncpu和物理页大小、还有其他的初始化操作
BL runtime·osinit(SB)
; 调用runtime.schedinit初始化调度器
; 其中会调用goargs函数将上面保存的argc和argv解析成字符串,保存到argslice变量,提供给os.Args供用户使用
BL runtime·schedinit(SB)
; 调用runtime.newproc,创建一个goroutine来执行runtime.main函数,用户的main就是由这个runtime.main调用的
MOVD $runtime·mainPC(SB), R0 // entry
SUB $16, RSP
MOVD R0, 8(RSP) // arg
MOVD $0, 0(RSP) // dummy LR
BL runtime·newproc(SB)
ADD $16, RSP
; 调用runtime.mstart开始调度器的循环调度,mstart应该是不会返回的,不然就会执行下面的...boom!异常退出
BL runtime·mstart(SB)
MOVD $runtime·debugCallV2<ABIInternal>(SB), R0
MOVD $0, R0
MOVD R0, (R0) ; boom
UNDEF
DATA runtime·mainPC+0(SB)/8,$runtime·main<ABIInternal>(SB)
GLOBL runtime·mainPC(SB),RODATA,$8
{: file=‘runtime/asm_arm64.s’}
上面这段汇编代码就是整个编译出来得到的二进制文件最开始执行的代码,主要干了下面几件事:
- 初始化启动参数
- 初始化并绑定g0和m0结构体
- 初始化os和调度器
- 创建一个新的g去运行runtime.main
- 调用
runtime.mstart开始调度循环
我们主要关注如何初始化调度器、如何创建g、如何调度循环。首先是runtime.schedinit。
初始化调度器
func schedinit() {
...
// 获取g0
gp := getg()
...
// 设置最大m数量为10000
sched.maxmcount = 10000
...
// 初始化m0并添加到allm中
mcommoninit(gp.m, -1)
...
// 初始化gc
gcinit()
// 调整p的数量为GOMAXPROCS
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
}
{: file=‘runtime/proc.go’}
调度器本身涉及到很多东西,比如gc、stack、cpu、os等,所以runtime.schedinit也负责初始化了一大堆东西,不过很多都暂时不用管,主要看一下runtime.procresize对allp的初始化。
runtime.procresize主要是调整p的数量为nprocs,绑定m0和p0,最后返回可以被调度的p:
func procresize(nprocs int32) *p {
...
// 调整allp大小,使其能容纳nprocs个p
if nprocs > int32(len(allp)) {
lock(&allpLock)
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
nallp := make([]*p, nprocs)
copy(nallp, allp[:cap(allp)])
allp = nallp
}
...
unlock(&allpLock)
}
// 创建p并初始化,p的初始化状态为_Pgcstop
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
// 如果m没有绑定p,或者已经绑定的p是非法的(下标超出nprocs-1)
// 1. 如果没有p或者p非法,将m和p解绑,并将m和p0绑定
// 2. 否则,这个已绑定的p可以看成p0(不一定下标为0才能是p0,只是这么叫而已)
gp := getg()
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
if gp.m.p != 0 {
...
gp.m.p.ptr().m = 0 // 解绑m0和p
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp) // 绑定m0和p0
...
}
...
// 销毁无用的p(下标超出nprocs-1的p)
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
}
...
// 将m0.p之外的p的状态都设成空闲_Pidle
// 将本地队列为空的p放到空闲链表
// 将剩下的p(本地队列不为空的p)返回作为将要被调度的p
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
...
return runnablePs
}
创建goroutine
除了在bootstrap的汇编代码中主动调用runtime.newproc之外,用户代码的go关键字也会被编译器转化对runtime.newproc的调用,所以无论是user的代码还是runtime的代码,其实都是放在g中由调度器来调度执行,从这个层面上来说没有什么区别。
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
// 在g0(系统栈)上运行
systemstack(func() {
// 创建并初始化g结构体
newg := newproc1(fn, gp, pc)
// 放入当前q的本地队列
pp := getg().m.p.ptr()
runqput(pp, newg, true)
// 如果main已经运行,唤醒新的p去调度g。对于bootstrap中调用newproc的时候,main还没运行
if mainStarted {
wakep()
}
})
}
看下runtime.newproc1将如何创建新的g:
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
...
// 获取一个优先的空闲g
// 用gfget优先从p本地空闲队列中取g,本地队列没有再从schedt全局空闲队列中取
// 本地队列和全局队列都没有的话再用malg创建一个新的栈大小为2K的g
mp := acquirem()
pp := mp.p.ptr()
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin) // stackMin=2K
...
}
...
// 初始化g
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
// 非常重要!这行和下面gostartcallfn这行,将g要执行代码的入口地址pc最终设成fn,以及执行完成后要的一下个执行地址lr最终被设成runtime.goexit的入口
// lr被设成goexit说明g执行结束后,会跳转到goexit去做我们的收尾工作
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
...
// 将g改成runnable状态
casgstatus(newg, _Gdead, _Grunnable)
gcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo))
// 每个g都有一个goid来唯一标识g,goid是从schedt.goidgen递增+1生成的,为了减对schedt.goidgen的并发访问,每次生成一批id缓存到p中
if pp.goidcache == pp.goidcacheend {
pp.goidcache = sched.goidgen.Add(_GoidCacheBatch)
pp.goidcache -= _GoidCacheBatch - 1
pp.goidcacheend = pp.goidcache + _GoidCacheBatch
}
newg.goid = pp.goidcache
pp.goidcache++
...
releasem(mp)
return newg
}
gp.sched是干什么的呢?我们将g看成是一个独立的执行单元(实际上就是这样的,goroutine嘛),那么就有自己的程序计数器pc、栈指针sp,返回地址lr等,都保存在gp.sched中。
回到runtime.newproc,g被获取到之后会调用runtime.runqput尝试放入p的本地队列当中:
func runqput(pp *p, gp *g, next bool) {
...
// 将g放到q.runnext中,作为q马上会调度运行的g
if next {
retryNext:
oldnext := pp.runnext
if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
gp = oldnext.ptr()
}
retry:
// 将g放到p的本地队列,如果本地队列满了,就放到全局队列
h := atomic.LoadAcq(&pp.runqhead)
t := pp.runqtail
if t-h < uint32(len(pp.runq)) {
pp.runq[t%uint32(len(pp.runq))].set(gp)
atomic.StoreRel(&pp.runqtail, t+1)
return
}
if runqputslow(pp, gp, h, t) {
return
}
goto retry
}
p.runq是个环形队列,p.runqhead和p.runqtail是头和尾的下标,不过这里的下标用法我还是第一次见,感觉非常nice,特此记录一下:一般来说下标会维护成不超过数组的大小,比如p.runqtail到达len(p.runq)-1后,下一个值应该是0,但这里对head和tail都只会递增,不会主动做取余回绕,在访问数组的时候才做个取余即可。另外下标是无符号数的话将非常方便获取队列大小,比如p.runqhead/p.runqtail都是uint32,因为整数本身也会溢出最大值回绕到0,比如head=(2^32)-5, tail=4,那么此时队列大小通过减法直接得出tail-head=9,非常好用;相反如果是有符号数int32,此时head=(2^31)-5, tail=4,要得出队列大小就稍微麻烦些了。
另外注意本地队列数据结构是固定长度的切片,而全局队列是个链表,因为全局队列中g的数量十分易变,所有p都能往里面放g或取g,用链表组织看起来更适合。
最后就是runtime.wakep函数,唤醒新的p去调度g,不过bootstrap过程中main还没启动,所以不会调用这个函数,可以先放着,等下再来分析,下面继续看bootstrap中的第三步,调度循环
调度循环
上面初始化调度器和创建goroutine都只是初始化调度器,其实还没真正开始用m来跑什么代码,汇编中调用的runtime·mstart才是真正启动m,去执行g的代码。runtime·mstart也是用汇编写的,其实是调用了用go写的runtime.mstart0:
TEXT runtime·mstart(SB),NOSPLIT|TOPFRAME,$0
BL runtime·mstart0(SB)
RET // not reached
{: file=‘runtime/asm_arm64.s’}
func mstart0() {
gp := getg()
// 初始化g0的栈
osStack := gp.stack.lo == 0
if osStack {
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
gp.stackguard0 = gp.stack.lo + stackGuard
gp.stackguard1 = gp.stackguard0
// 启动m
mstart1()
// Exit this thread.
if mStackIsSystemAllocated() {
// Windows, Solaris, illumos, Darwin, AIX and Plan 9 always system-allocate
// the stack, but put it in gp.stack before mstart,
// so the logic above hasn't set osStack yet.
osStack = true
}
mexit(osStack)
}
runtime.mstart0主要就是初始化g0系统栈,调用runtime.mstart1去启动m,最后做退出m的收尾工作,注意runtime.mstart1不会返回,只有当g锁定了m的时候,才会直接在g上执行,然后返回调用runtime.mstart1的那行代码的下一行代码,执行runtime.mexit。继续看runtime.mstart1:
func mstart1() {
gp := getg()
// 调度都是发生在系统堆栈上的,即g0,所以要检查一下
if gp != gp.m.g0 {
throw("bad runtime·mstart")
}
// 下面调用的schedule不会返回,因此这里用了类似尾调用的手段,将mstart0中调用mstart1那行代码的pc保存起来,在goexit0中会直接回到mstart0中去运行mexit来完成m的退出。
gp.sched.g = guintptr(unsafe.Pointer(gp))
gp.sched.pc = getcallerpc()
gp.sched.sp = getcallersp()
// 初始化信号处理相关的东西
asminit()
minit()
if gp.m == &m0 {
mstartm0()
}
// 执行m的起始函数
// 通过查找mstartfn在哪被赋值可以发现,m0是没有mstartfn的
if fn := gp.m.mstartfn; fn != nil {
fn()
}
// 如果当前不是m0,绑定m和m.nextp。m0来说是没有p的,所以不用绑定
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
// 开始调度
schedule()
}
runtime.mstart1主要是设置g.sched、初始化信号处理、执行m的起始函数mstartfn。前面做了那么多准备工作,runtime.schedule才是真正做调度工作:
func schedule() {
mp := getg().m
...
// 如果有g必须在当前m上执行,不能有其他g执行,那么直接执行那个g就行,不用调度其他g
// 一般只有runtime.LockOSThread调用后,m.lockedg才有值
if mp.lockedg != 0 {
stoplockedm()
execute(mp.lockedg.ptr(), false) // Never returns.
}
...
top:
pp := mp.p.ptr()
pp.preempt = false
// 一致性检查:如果m处于自旋状态,那么p不应该有等待被调用的g
// 关于m的自旋状态,在proc.go文件的开头注释有一段说明:m不正在执行任务,并且当本地队列、全局队列、netpoller也没有任务。
if mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
throw("schedule: spinning with local work")
}
// 寻找可调度的g,阻塞在这里直到找到g
gp, inheritTime, tryWakeP := findRunnable()
...
// 如果m本来是自旋状态(找不到g运行),现在已经找到g了,取消自旋
// 并且如果这是唯一一个自旋中的m,那么将会再去启动一个m去让他自旋(原因见"Worker thread parking/unparking"的注释)
if mp.spinning {
resetspinning()
}
...
// 如果被调度的g比较特殊(比如gc、trace相关),唤醒新的p去专门处理这些特殊的g
if tryWakeP {
wakep()
}
// 如果g指定在某个m上运行,将p转移到指定的m上,然后park阻塞当前m去运行指定m
// 运行完后再把p拿回来,重新走一遍上面流程
if gp.lockedm != 0 {
startlockedm(gp)
goto top
}
// 执行g
execute(gp, inheritTime)
}
runtime.schedule主要是获取g,然后调runtime.execute去执行g。这里runtime.findrunnable比较复杂,但是不影响主流程,回过头再分析,大概知道它会从本地队列、全局队列、netpoller这些地方去获取g就可以了。下面继续看runtime.execute:
func execute(gp *g, inheritTime bool) {
mp := getg().m
...
// 绑定m和g,将g设置为_Grunning
mp.curg = gp
gp.m = mp
casgstatus(gp, _Grunnable, _Grunning)
...
if !inheritTime {
// 如果是新的时间片,记录p的调度次数+1
mp.p.ptr().schedtick++
}
...
// 完成从g0到g的切换
gogo(&gp.sched)
}
runtime.execute中,参数inheritTime意思是是否使用g剩下的时间片,否则就重新运行一个完整的时间片,这个参数是runtime.findrunnable来决定的。继续看重头戏runtime.gogo,这个函数是用汇编写的:
TEXT runtime·gogo(SB), NOSPLIT|NOFRAME, $0-8
MOVD buf+0(FP), R5
MOVD gobuf_g(R5), R6
MOVD 0(R6), R4 // make sure g != nil
; 调用gogo<>(gobuf.g), gobuf就是传入的gp.sched
B gogo<>(SB)
TEXT gogo<>(SB), NOSPLIT|NOFRAME, $0
MOVD R6, g
; 调用runtime·save_g,将g保存到tls
BL runtime·save_g(SB)
; 从g0切换到g的上下文(栈、返回地址等)
MOVD gobuf_sp(R5), R0
MOVD R0, RSP
MOVD gobuf_bp(R5), R29
MOVD gobuf_lr(R5), LR
MOVD gobuf_ret(R5), R0
MOVD gobuf_ctxt(R5), R26
; 清空gobuf的上述字段
MOVD $0, gobuf_sp(R5)
MOVD $0, gobuf_bp(R5)
MOVD $0, gobuf_ret(R5)
MOVD $0, gobuf_lr(R5)
MOVD $0, gobuf_ctxt(R5)
CMP ZR, ZR // set condition codes for == test, needed by stack split
; 跳转到gobuf.pc去执行
MOVD gobuf_pc(R5), R6
B (R6)
终于找到了,调度的关键就在于最后那两行!跳转到g的pc!跳转过去执行完毕后,会跳转到gobuf.lr。关于pc和lr在之前分析runtime.newproc的时候就能找到,截出来看一下:
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
...
// 非常重要!这行和下面gostartcallfn这行,将g要执行代码的入口地址pc最终设成fn,以及执行完成后要的一下个执行地址lr最终被设成runtime.goexit的入口,即g执行结束后,会跳转到goexit去做我们的收尾工作
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
...
}
跳转到pc后,就是去执行g的代码了,执行完之后,就会跳转到runtime.goexit,老规矩,没有函数体就是用汇编写的,其实是直接跳转到runtime.goexit1:
func goexit1() {
...
mcall(goexit0)
}
代码省略的部分是race和trace相关,我们关注runtime.mcall(goexit0),runtime.mcall也是汇编写的,作用是切换到从g切换到g0去执行fn,这个fn不会返回,而是最终会调用runtime.gogo来继续执行g。
所以runtime.goexit1是切换到g0(系统栈)上去执行runtime.goexit0。runtime.goexit0:
func goexit0(gp *g) {
mp := getg().m
pp := mp.p.ptr()
// 将g的状态设为_Gdead
casgstatus(gp, _Grunning, _Gdead)
// g所用的栈可被gc扫描回收
gcController.addScannableStack(pp, -int64(gp.stack.hi-gp.stack.lo))
// 设置一些全局状态、置空g的一些成员
if isSystemGoroutine(gp, false) {
sched.ngsys.Add(-1)
}
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
mp.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = waitReasonZero
gp.param = nil
gp.labels = nil
gp.timer = nil
...
// 解绑m和g
dropg()
...
// 将g放入p的空闲队列,以便下次可以通过runtime.gfget复用不用每次都创建新的g
gfput(pp, gp)
...
// 调度循环,调度下一个g运行
schedule()
}
经过上面的一步步分析,「整个程序的启动创建g0->跳转到g并执行->调度下一个g执行」形成了一个调度循环的闭环。实际情况会更加复杂,上面所说的只是正常调度的流程,省略了很多分支情况,比如g在执行的过程中会经历协作式或者抢占式调度,它会让出线程的使用权等待调度器的唤醒。
主流程上其实还有很多悬而未决的问题:
- 为了充分利用多核并行能力,必然要启动多个m,那么m是什么时候启动的,进一步地说,m的生命周期是怎么样的?
runtime.findrunnable决定了下一个要运行的g,是调度策略的核心,那么他将如何选择g?
先分析下m的生命周期,首先m通过runtime.startm启动,这个函数在好几个地方会被调用:
runtime.handoffp:将p与阻塞的m解绑,去寻找非阻塞的m绑定runtime.wakep:唤醒p去调度gruntime.injectglist:将一些可运行的g放到本地队列/全局队列,让他们得以调度运行runtime.sysmon:系统监控,包括gc、netpoll、preemption等runtime.schedEnableUser:gc时停止调度用户的g
其中runtime.handoffp可以在syscall阻塞m的时候才进行分析,runtime.injectglist在好几个地方也会被调用,功能比较通用/泛化,也暂时不看,runtime.sysmon是系统监控相关,可以专门放到一个小节来分析,最后runtime.schedEnableUser是gc相关,不是这里的重点。目前“最熟悉”的是runtime.wakeup,这个函数在runtime.newproc和runtime.schedule都有调用,因此先看一下这个runtime.wakep:
func wakep() {
// 如果已经有自旋的m,就什么都不做
if sched.nmspinning.Load() != 0 || !sched.nmspinning.CompareAndSwap(0, 1) {
return
}
mp := acquirem()
var pp *p
lock(&sched.lock)
// 尝试获取一个空闲的p
pp, _ = pidlegetSpinning(0)
if pp == nil {
if sched.nmspinning.Add(-1) < 0 {
throw("wakep: negative nmspinning")
}
unlock(&sched.lock)
releasem(mp)
return
}
unlock(&sched.lock)
// 启动m
startm(pp, true, false)
releasem(mp)
}
看起来runtime.wakep好像没做什么,只是去获取了一个空闲p然后传给runtime.startm。继续看runtime.startm
func startm(pp *p, spinning, lockheld bool) {
...
// wakep传进来的pp不会是nil,暂时忽略pp==nil的处理
if pp == nil {
...
}
// 从全局m空闲链表获取一个空闲的m,如果获取不到,调用runtime.newm创建新的m
nmp := mget()
if nmp == nil {
...
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
// 创建m
newm(fn, pp, id)
...
return
}
...
// 唤醒这个空闲的m
nmp.spinning = spinning
nmp.nextp.set(pp)
notewakeup(&nmp.park)
releasem(mp)
}
所以runtime.wakep是唤醒一个p并唤醒/创建一个m,m会处于自旋状态,自旋的m会去找p绑定。继续看runtime.newm是怎么创建m的:
func newm(fn func(), pp *p, id int64) {
acquirem()
// 创建一个m结构体
mp := allocm(pp, fn, id)
mp.nextp.set(pp)
mp.sigmask = initSigmask
...
// 创建m对应的线程
newm1(mp)
releasem(getg().m)
}
func newm1(mp *m) {
if iscgo {
...
}
execLock.rlock() // Prevent process clone.
// 创建系统线程
newosproc(mp)
execLock.runlock()
}
runtime.newm主要是创建m结构体,runtime.newm1是cgo相关的处理代码,然后调用runtime.newosproc创建系统线程:
func newosproc(mp *m) {
stk := unsafe.Pointer(mp.g0.stack.hi)
...
// 发起系统调用创建系统线程运行runtime.mstart
ret := retryOnEAGAIN(func() int32 {
r := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(abi.FuncPCABI0(mstart)))
// clone returns positive TID, negative errno.
// We don't care about the TID.
if r >= 0 {
return 0
}
return -r
})
sigprocmask(_SIG_SETMASK, &oset, nil)
// 错误处理
if ret != 0 {
print("runtime: failed to create new OS thread (have ", mcount(), " already; errno=", ret, ")\n")
// linux不严格区分进程和线程,这里是提示让我们用ulimit -u提高用户进程数上限
if ret == _EAGAIN {
println("runtime: may need to increase max user processes (ulimit -u)")
}
throw("newosproc")
}
}
线程创建之后,会去跑runtime.mstart,随后就是进入调度循环了(但也有的线程不参与调度工作,而是去做别的工作,比如runtime.sysmon)
经过一番的代码跟踪,对整个调度流程有了个大概的认知:首先proc.go里有全局变量m0,作为我们整个程序的第一个m,以及作为m0的g0(注意每个m都有自己的g0,g0所占有的栈即系统栈,调度行为是发生在系统栈上的)。进入bootstrap后,创建了第一个g,这个g用来runtime.main,在这个函数中会进入用户的main运行。每次创建新的g,都可能会创建新的p的和新的m来调度运行g,每个m都在进行着自己的调度循环。调度循环并不是指for循环,而是下面的三部曲:
schedule:负责调度策略,决定下一个调度的ggogo:执行从g0切换到g去执行,设置g的返回地址为goexitgoexit:清理这个执行完毕的g,调用schedule进行新一轮的调度
runtime.findrunnable
上个小节主要用来理清调度循环,这个小节攻克调度策略的实现,即runtime.findrunnable:
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
...
// 尝试获取gc worker的g
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
// 每调度60次就尝试一次获取全局队列的g,以免由于全局队列优先级较低而导致其中的g饥饿
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// 唤醒finalizer的g
if fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake {
if gp := wakefing(); gp != nil {
ready(gp, 0, true)
}
}
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// 尝试从本地队列获取g
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// 尝试从全局队列获取g
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
// 尝试从netpoller获取一批g,返回其中第一个g,其他g放到队列中
if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
}
// 如果m处于自旋或者自旋的m相对于空闲的p不够多,尝试随机从其他p的本地队列偷一半的g(这里timer没理解是什么东西,以后有时间再看)
if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {
if !mp.spinning {
mp.becomeSpinning()
}
gp, inheritTime, tnow, w, newWork := stealWork(now)
if gp != nil {
// Successfully stole.
return gp, inheritTime, false
}
if newWork {
// There may be new timer or GC work; restart to
// discover.
goto top
}
now = tnow
if w != 0 && (pollUntil == 0 || w < pollUntil) {
// Earlier timer to wait for.
pollUntil = w
}
}
// 又是gc worker相关的,看不懂,不过这次的g不再属于特殊g(tryWakep=false)
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
// Before we drop our P, make a snapshot of the allp slice,
// which can change underfoot once we no longer block
// safe-points. We don't need to snapshot the contents because
// everything up to cap(allp) is immutable.
allpSnapshot := allp
// Also snapshot masks. Value changes are OK, but we can't allow
// len to change out from under us.
idlepMaskSnapshot := idlepMask
timerpMaskSnapshot := timerpMask
// return P and block
lock(&sched.lock)
if sched.gcwaiting.Load() || pp.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
// 再次检查全局队列,发现有g就返回
if sched.runqsize != 0 {
gp := globrunqget(pp, 0)
unlock(&sched.lock)
return gp, false, false
}
// 如果需要m自旋,那么m变为自旋状态然后再走一遍流程
if !mp.spinning && sched.needspinning.Load() == 1 {
// See "Delicate dance" comment below.
mp.becomeSpinning()
unlock(&sched.lock)
goto top
}
// 解绑当前m和p
if releasep() != pp {
throw("findrunnable: wrong p")
}
now = pidleput(pp, now)
unlock(&sched.lock)
wasSpinning := mp.spinning
// 首先关闭m的自旋,再次检查有没有g可以偷的p,有的话就再次变为自旋状态然后再走一遍流程
// 否则去检查有没有空闲gc worker,有的话就返回gc worker的g
if mp.spinning {
mp.spinning = false
if sched.nmspinning.Add(-1) < 0 {
throw("findrunnable: negative nmspinning")
}
pp := checkRunqsNoP(allpSnapshot, idlepMaskSnapshot)
if pp != nil {
acquirep(pp)
mp.becomeSpinning()
goto top
}
// Check for idle-priority GC work again.
pp, gp := checkIdleGCNoP()
if pp != nil {
acquirep(pp)
mp.becomeSpinning()
// Run the idle worker.
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil)
}
// 再次尝试从netpoller获取g
if netpollinited() && (netpollWaiters.Load() > 0 || pollUntil != 0) && sched.lastpoll.Swap(0) != 0 {
...
list := netpoll(delay) // block until new work is available
// 如果没获取到g,那么m就休眠(变成空闲的m)
if faketime != 0 && list.empty() {
stopm()
goto top // m唤醒后再走一遍流程
}
lock(&sched.lock)
pp, _ := pidleget(now)
unlock(&sched.lock)
if pp == nil {
injectglist(&list)
} else {
acquirep(pp)
if !list.empty() {
// 如果获取到了g就返回
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if traceEnabled() {
traceGoUnpark(gp, 0)
}
return gp, false, false
}
if wasSpinning {
mp.becomeSpinning()
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := sched.pollUntil.Load()
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
// 不太理解这里,我猜应该是已经知道了netpoll没有东西返回,直接让其他也在等netpoll的线程也别等了
netpollBreak()
}
}
// m休眠,唤醒后再走一遍流程
stopm()
goto top
}
首先自旋意味着不干活,但是会不断检查有没有活可以干,是一个不断耗cpu的状态,但耗时极短,可能只有一瞬间处于自旋。在自旋这个窗口期内,其他并发的线程通过检查有没有线程处于自旋状态,以避免其启动不必要的线程。
总的来说就是按照优先级从几个地方获取g:
- 本地队列(每60次调度会优先从全局队列获取g,避免全局队列的g饥饿)
- 全局队列
- netpoller
- work-stealing(从其他p的本地队列偷)
runtime.gopark / runtime.goready
channel、netpoller等都是基于gmp来进行阻塞和调度运行的,channel就不多说了,之前分析channel的时候,netpoller通过设置非阻塞模式,将本来应该阻塞系统线程变成了阻塞g,大大降低了上下文切换成本和提高了系统线程的利用率。
而线程就一直不会阻塞吗?不是的,runtime.findrunnable在找不到可运行的g的时候,就使用了runtime.stopm来阻塞m,在linux平台上其内部是通过futex实现的系统线程阻塞的。
另外,runtime.gopark是几种触发调度方式的其中一种,属于主动挂起。之前还说到调度循环启动的runtime.mstart以及g运行结束后的runtime.goexit也会触发调度。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// 切换到g0,调用runtime.park_m
mcall(park_m)
}
func park_m(gp *g) {
...
// 设置g的状态为_Gwaiting,解绑m和g
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
// 调用gopark传入的回调函数,返回false代表外界不想阻塞了,于是会继续执行g,不会阻塞
if fn := mp.waitunlockf; fn != nil {
ok := fn(gp, mp.waitlock)
mp.waitunlockf = nil
mp.waitlock = nil
if !ok {
if traceEnabled() {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
// 触发调度其他g
schedule()
}
再来看下runtime.goready,和runtime.gopark本质上都是将g的状态改成runnable或者waiting,然后让调度器去调度可运行的g:
func goready(gp *g, traceskip int) {
// 切换到系统栈上执行,
systemstack(func() {
ready(gp, traceskip, true)
})
}
func ready(gp *g, traceskip int, next bool) {
...
// 将g的状态设成可运行,放到队列中,唤醒p,等待下一次调度
casgstatus(gp, _Gwaiting, _Grunnable)
runqput(mp.p.ptr(), gp, next)
wakep()
releasem(mp)
}
注意runtime.gopark使用runtime.mcall切换到g0执行,所执行的函数是不会返回的。而runtime.goready使用的是runtime.systemstack切换到系统栈执行一段代码,然后返回到当前g继续执行。
runtime.sysmon
在程序启动的时候,会创建一个新的线程m,同时创建一个协程g,这个g不需要绑定p,直接与m绑定,也就是所谓的sysmon协程,sysmon充当一个守护进程的角色,比如会做检查死锁、轮询网络、抢占长期运行或者处于系统调用的 Goroutine、触发垃圾回收等操作,协助系统的运行。
func main() {
...
if GOARCH != "wasm" { // no threads on wasm yet, so no sysmon
atomic.Store(&sched.sysmonStarting, 1)
// 直接调用newm启动线程执行sysmon,不需要p
systemstack(func() {
newm(sysmon, nil, -1)
})
}
...
}
sysmon运行在一个无限循环中,每次循环的开始会runtime.usleep主动休眠一会,如果抢占 P 和 G 失败次数超过50轮、且没有触发 GC,则说明很闲,翻倍休眠,最多10ms。
func sysmon() {
lock(&sched.lock)
sched.nmsys++
// 检查死锁
checkdead()
unlock(&sched.lock)
lasttrace := int64(0)
idle := 0 // how many cycles in succession we had not wokeup somebody
delay := uint32(0)
for {
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
...
lock(&sched.sysmonlock)
now = nanotime()
...
// 如果超过10ms没有poll网络,poll一下
lastpoll := sched.lastpoll.Load()
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
sched.lastpoll.CompareAndSwap(lastpoll, now)
list := netpoll(0) // non-blocking - returns list of goroutines
if !list.empty() {
// poll到g了,放到全局队列
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}
...
// 抢占处于系统调用的m上的p,以及抢占长时间运行的g
if retake(now) != 0 {
idle = 0
} else {
idle++
}
// 检查是否要gc,要的话就将gc worker加入全局队列
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() {
lock(&forcegc.lock)
forcegc.idle.Store(false)
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
...
}
}
runtime.retake实现了g的抢占、p使用权的让出,避免同一个g占用线程时间过长造成饥饿
func retake(now int64) uint32 {
n := 0
...
for i := 0; i < len(allp); i++ {
pp := allp[i]
...
pd := &pp.sysmontick
s := pp.status
sysretake := false
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(pp.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
// 如果g处于运行或者系统调用超过10ms,就抢占m,让m去调度其他的g
preemptone(pp)
sysretake = true
}
}
// p本地队列不为空或者没有空闲p,或者系统调用超过10ms,就使用runtime.handoff让出p使用权,让p去绑定其他m,让p中的g得以继续调度
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(pp.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
if runqempty(pp) && sched.nmspinning.Load()+sched.npidle.Load() > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// Drop allpLock so we can take sched.lock.
unlock(&allpLock)
// Need to decrement number of idle locked M's
// (pretending that one more is running) before the CAS.
// Otherwise the M from which we retake can exit the syscall,
// increment nmidle and report deadlock.
incidlelocked(-1)
if atomic.Cas(&pp.status, s, _Pidle) {
if traceEnabled() {
traceGoSysBlock(pp)
traceProcStop(pp)
}
n++
pp.syscalltick++
handoffp(pp)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
// 返回被抢占p的数量
return uint32(n)
}
常见面试题
GMP为什么要有P
如果没有P,即GM模型。go确实经历过GM模型,后来大神提出了这个模型存在的问题:
- 单一的g全局队列,导致锁竞争严重
- m之间经常交接可运行的g,导致延迟增加和额外开销
- 每个m都需要做内存缓存mcache,导致数据局部性差
- 系统调用频繁阻塞和唤醒线程,增加开销
参考链接🔗
【lunar@qq.com】Golang 1.21.4 GMP调度器底层实现个人走读
【panjf2000】Go 网络模型 netpoll 全揭秘
【stack overflow】Benefits of runtime.LockOSThread in Golang